

2022年11月,OpenAI推出了基于GPT-3.5打造的ChatGPT,引燃了大模型浪潮,进而引起全球AI竞赛。海内外不少头部互联网公司和人工智能公司基本都对外发布了自家的大模型,中国更是出现了“百模大战”的局面。
根据AI算法备案中心统计,截至2024年3月28日,国内通过算法备案的大模型数量达117个。其中不乏我们熟悉的百度“文心一言”、阿里巴巴“通义千问”、商汤科技“日日新”,还有我们今天要聊的字节跳动“豆包大模型”(原名:云雀)。
揭秘豆包大模型家族架构
豆包大模型经过近一年的迭代和市场验证,今日终于正式开启对外服务。在2024春季火山引擎Force原动力大会上,字节跳动揭开了豆包大模型神秘的面纱,据介绍,豆包大模型包括通用模型pro、通用模型lite、语音识别模型、语音合成模型、文生图模型等九款模型。

图源:字节跳动
具体应用方面,字节跳动打造了AI对话助手“豆包”、AI创作工具“即梦”、AI应用开发平台“扣子”等一系列应用,并将大模型接入抖音、飞书、巨量引擎等业务板块,用以提升效率和优化产品体验。
豆包作为字节跳动重点投入的大模型应用,据字节跳动产品和战略副总裁朱骏透露,豆包APP在各大安卓应用市场和苹果APP Store的AIGC类应用中,下载量排名第一,月活用户达2600万。
此前小雷特地体验了以图片、视频生成为核心卖点的AI创作工具即梦,对豆包大模型的实力深有体会。即梦虽然在视频生成方面仍有待优化,但图片生成已经达到了不错的水准,这让小雷对豆包充满期待,究竟被字节跳动寄予厚望的豆包是什么样的水平,不妨跟着小雷一起看看。
豆包轻体验,全应用强调延伸性
豆包在移动端、PC端都有布置应用入口,小雷在体验过程中发现原来豆包在Windows/Mac桌面客户端以及浏览器插件方面均有布局。为了方便体验,小雷选择了PC网页端作为体验对象。
图源:豆包
进入网页端首页,豆包优先向我推荐了三个不同类型的AI应用,分别为AI搜索、PDF问答、图像生成,这可能是用户使用频次最高的应用。既然如此,小雷找来了同样定位智能助手的Kimi,来看看这AI搜索和PDF问答的成色,小雷已经在即梦上体验过图像生成,这次就不重复体验了,两者都接入了豆包大模型,表现应该相差不大。
强强对话之下,相信大家会对豆包大模型有更直观的感受。
图源:豆包
AI搜索:各有长短,豆包赢在效率和问题延伸性
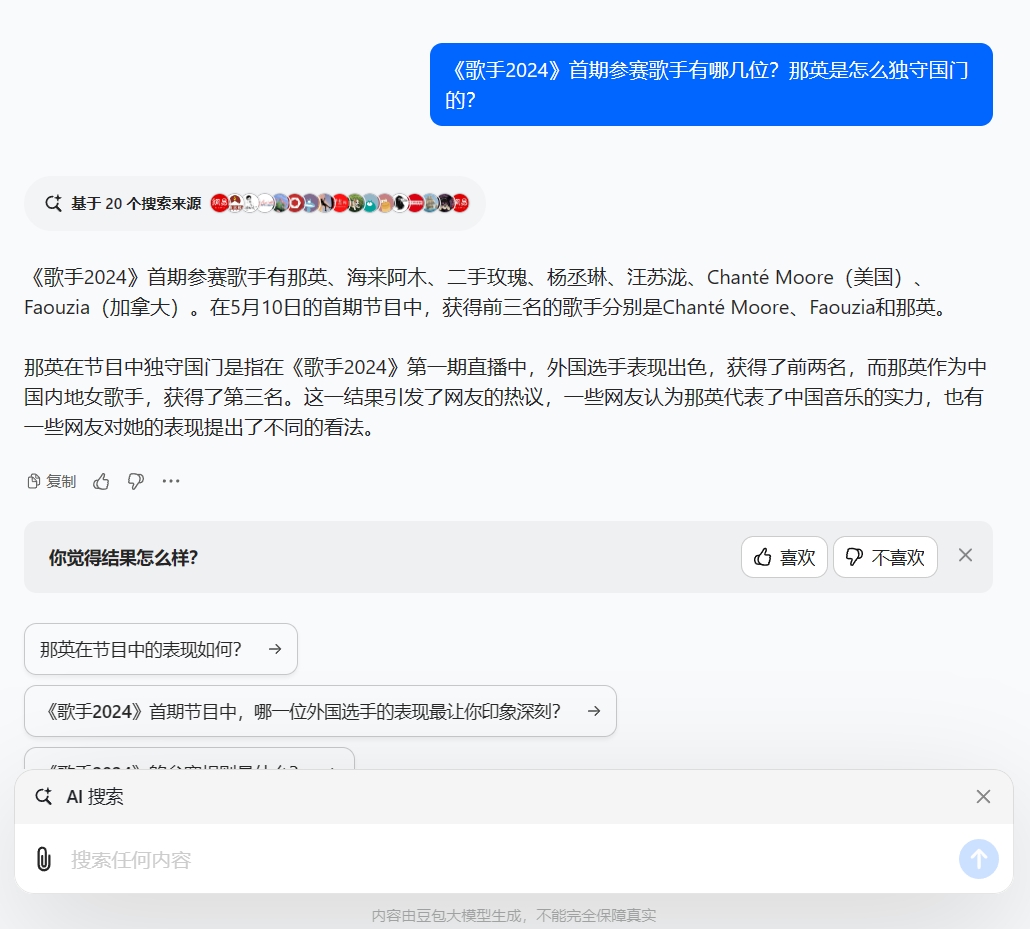
最近《歌手2024》火遍全网,话题性极高的中外歌手比拼引起不少网友热议,小雷就此问题向豆包、Kimi提问。
豆包花费数秒就给出了回答及搜索来源,回答内容没有出现常识性错误,选手信息和排名十分清晰,对调侃式的互联网热梗也能准确识别并作出解释。延伸性是AI搜索的精髓之一,这点也在回答下方的得到展示。
相对来说,豆包用非常精简语句总结了我们想要知道的答案。
图源:豆包
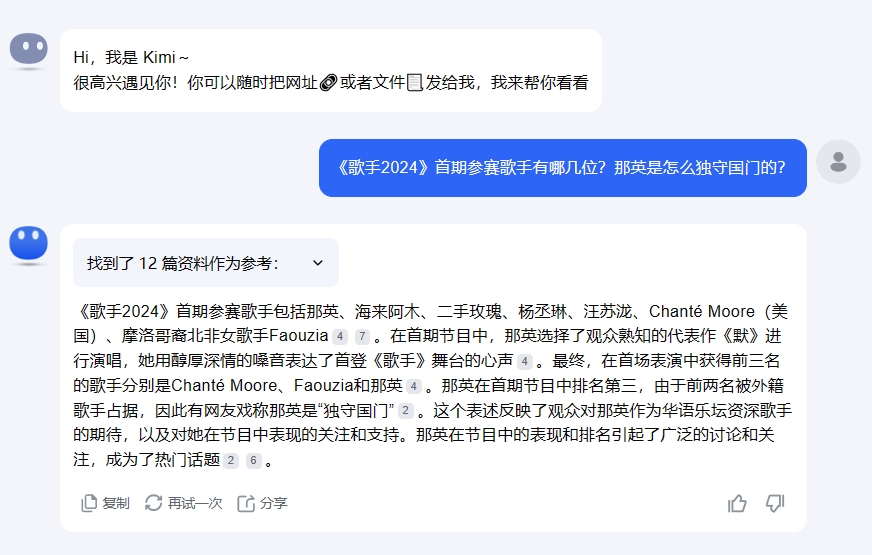
Kimi在这块相对好些,问题解释比较详细,在每个回答内容处标注了资料来源,这能为用户省下不少翻查信息来源的时间。生成效率方面,Kimi的表现不如豆包,大约用了10s才给出了回答,并且没有给出该问题的延伸问题,这对于一个智能助手来说是个不小的问题。
图源:Kimi
PDF问答:豆包惊喜,Kimi稳定
长文本处理是Kimi的强项,在之前的体验中小雷让其总结了《过于喧闹的孤独》书籍的PDF文件,字数在10万左右。这次豆包的处理对象依旧是它,看看同样的指令处理同一份PDF文件,豆包又能交出怎样的答卷。
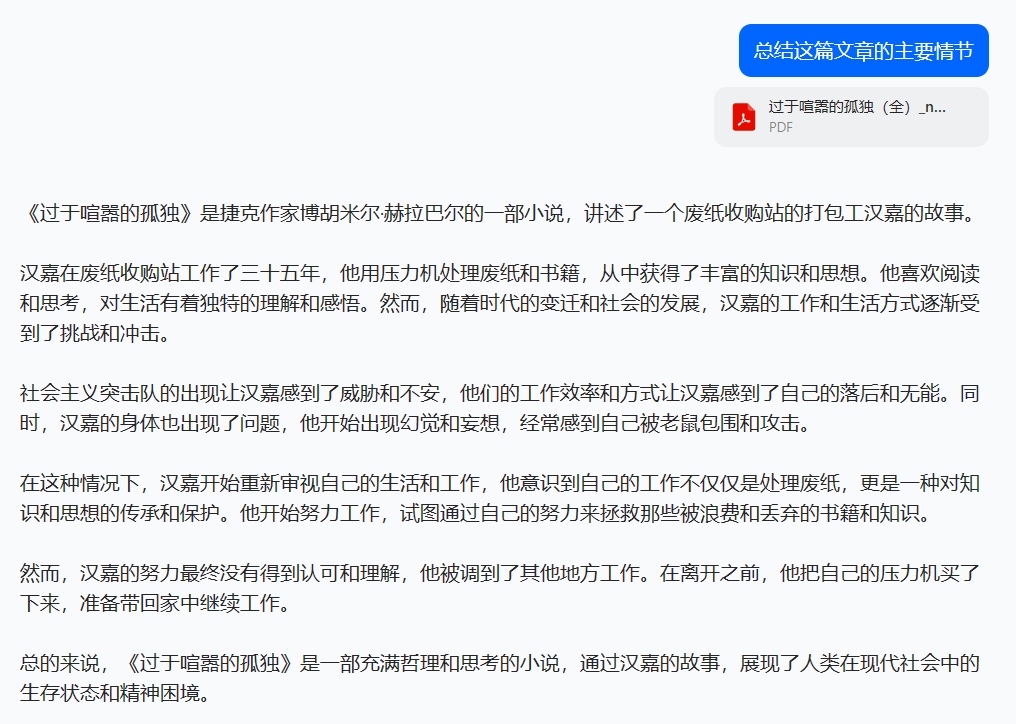
图源:豆包
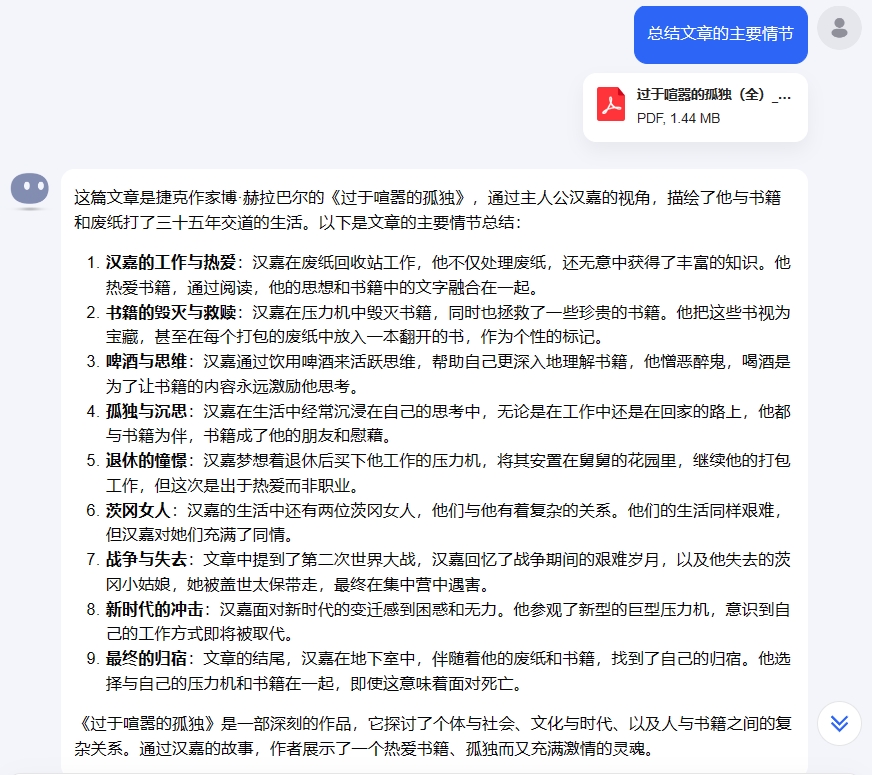
图源:Kimi
Kimi对文章主要情节做了分段处理,每段内容提供段落小结,回答的开头结尾就文章内容和寓意给出了确切的回答;豆包则是以文章的形式进行表达,将文章内容浓缩简短的故事,大意与Kimi基本一致,最后给出自己的理解。有趣的是,豆包还是遵循着延伸性搜索的好习惯,下方提供了3个与文章相关的搜索。
总的来说,两者在准确识别PDF文件内容的同时,对内容进行了总结,文章关键点基本提及。差别在于大模型的处理逻辑,这导致回答的内容形式产生了区别,没有优劣之分,用户使用该功能只为获得准确的答案。不过受限于资料,小雷没来得及准备更大文本量的PDF,因此无法试探豆包长文本处理能力的极限,感兴趣的朋友可以自行实践体验。
除了常见的AI应用外,小雷发现豆包还隐藏了许多有趣的智能体。有角色扮演、文案助手以及各类测试等智能体,数量、品类之多足以覆盖生活、工作、学习、创作等诸多场景。用户也可以选择打造专属于自己的AI智能体,自由设定头像、名称、人设以及权限。当然,小雷在之前已经对豆包做过深度评测,从多个维度试探了豆包在各场景下的实力,感兴趣的朋友可以点击查阅。
图源:豆包
此前,小雷在文心一言上创建了内置AI声音的智能体,豆包APP已经有类似的应用,而豆包网页端倒是没有看到相关设定,或许后续会结合豆包大模型家族中的语音合成模型、声音复刻模型、语音识别模型进行迭代,让网页端AI智能体更拟人。
大模型价格步入“厘时代”,AIGC应用场景加速落地
过去一年,豆包大模型已经在字节跳动内部50多个业务和场景中得到广泛应用,不少用户使用抖音、飞书时发现了豆包的身影。据了解,豆包大模型自去年8月份上线以来,日均处理1200亿Tokens文本,生成3000万张图片,而庞大的内部使用量正是为了更好的实现外部服务。
大模型+应用产品共同发布,是大多数大模型玩家的习惯,豆包大模型则正好相反,投入使用一年才正式发布。或许是为了积累更庞大的数据使用量,又或者是为了更完美的首秀,总之字节跳动有一套清晰的大模型战略,并不会因为外界比较就随意调整。
在本次发布会上,字节跳动没有放出任何榜单分数和参数规模,反而着重强调了豆包大模型加速落地的另一重要因素:价格。豆包主力模型在企业市场的定价只有0.0008元/千Tokens,0.8厘就能处理1500多个汉字,比行业便宜99.3%,简单换算一下,1元就能处理1250000tokens,价格远低于GPT4、ERINE4.0、Qwen 2.5 Max等其他大模型处理成本。
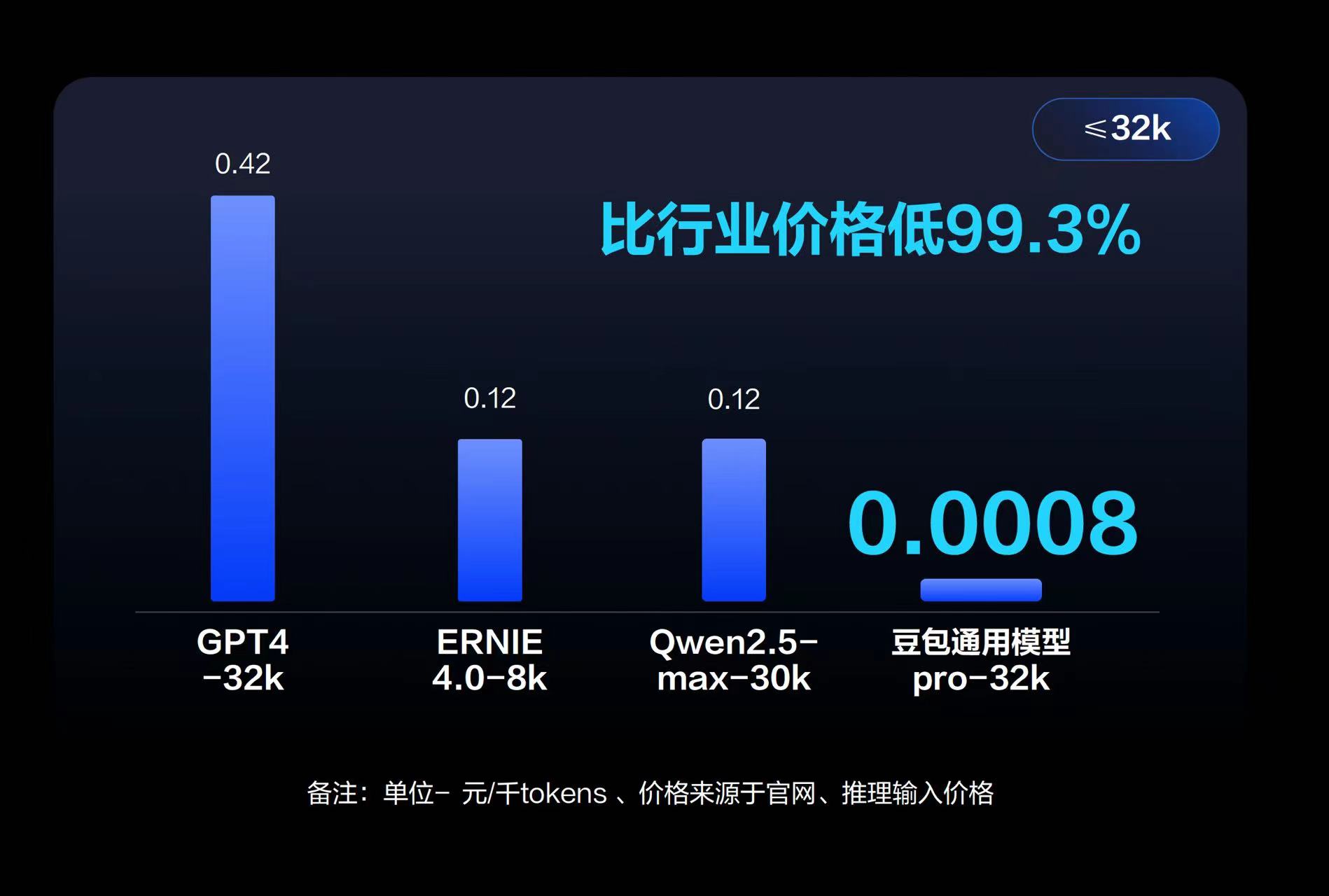
图源:字节跳动
结合体验,小雷感受到了字节跳动的底气所在,那就是行业大模型平均线以上的水准+远低于行业的处理成本。对于任何一家有意发展大模型企业来说,这两点具备绝佳的吸引力。目前豆包大模型在B端已收获了不少的合作伙伴,来自汽车、手机、PC等行业的众多企业均已接入火山引擎的大模型服务,包括吉利汽车、赛力斯、vivo、小米、华硕等。在高性价比落地价格的推动下,未来接入大模型的企业会越来越多。
当前大模型应用发展仍处于早期阶段。QuestMobile数据显示,截至今年3月,基于大模型的AIGC行业用户量为7380万,同比增长了8倍,仅占移动互联网用户量的6%,存在广阔的增长空间。字节跳动极具竞争力的定价在冲击行业之余,势必给AIGC应用创造低成本的落地条件。
背靠字节跳动的豆包大模型,是时候让AIGC应用场景落地提提速了。





